Corpus Christi Tide Charts
Corpus Christi Tide Charts - For corpora other than hkcancor, pycantonese provides the function read_chat () to read in. The beijing language and culture university created a balanced corpus of 15 billion characters. Adding them meaningfully to dictionary. The beijing language and culture university created a balanced corpus of 15 billion characters. I would read in the bcc corpus frequency list as a dictionary, then having concatenated all the news/magazine articles as plain text, i would build a dictionary of all the. Recently i've been studying some colloquial stuff and have found that not only. Hey mike, i'm a big user of vocab lists and i'm about 1.5 months away from finishing the hsk4 list. The bcc corpus seems to have pretty loose licensing terms. Pleco already seems to be using frequency data to sort the search results. The beijing language and culture university created a balanced corpus of 15 billion characters. The beijing language and culture university created a balanced corpus of 15 billion characters. For corpora other than hkcancor, pycantonese provides the function read_chat () to read in. Pleco already seems to be using frequency data to sort the search results. I would read in the bcc corpus frequency list as a dictionary, then having concatenated all the news/magazine articles as plain text, i would build a dictionary of all the. The beijing language and culture university created a balanced corpus of 15 billion characters. Hey mike, i'm a big user of vocab lists and i'm about 1.5 months away from finishing the hsk4 list. Recently i've been studying some colloquial stuff and have found that not only. The beijing language and culture university created a balanced corpus of 15 billion characters. Adding them meaningfully to dictionary. The bcc corpus seems to have pretty loose licensing terms. The bcc corpus seems to have pretty loose licensing terms. I would read in the bcc corpus frequency list as a dictionary, then having concatenated all the news/magazine articles as plain text, i would build a dictionary of all the. The beijing language and culture university created a balanced corpus of 15 billion characters. Pleco already seems to be using. Hey mike, i'm a big user of vocab lists and i'm about 1.5 months away from finishing the hsk4 list. The beijing language and culture university created a balanced corpus of 15 billion characters. The beijing language and culture university created a balanced corpus of 15 billion characters. Recently i've been studying some colloquial stuff and have found that not. The beijing language and culture university created a balanced corpus of 15 billion characters. Hey mike, i'm a big user of vocab lists and i'm about 1.5 months away from finishing the hsk4 list. The beijing language and culture university created a balanced corpus of 15 billion characters. I would read in the bcc corpus frequency list as a dictionary,. Hey mike, i'm a big user of vocab lists and i'm about 1.5 months away from finishing the hsk4 list. The bcc corpus seems to have pretty loose licensing terms. Pleco already seems to be using frequency data to sort the search results. Recently i've been studying some colloquial stuff and have found that not only. The beijing language and. I would read in the bcc corpus frequency list as a dictionary, then having concatenated all the news/magazine articles as plain text, i would build a dictionary of all the. Recently i've been studying some colloquial stuff and have found that not only. The bcc corpus seems to have pretty loose licensing terms. The beijing language and culture university created. Recently i've been studying some colloquial stuff and have found that not only. Adding them meaningfully to dictionary. For corpora other than hkcancor, pycantonese provides the function read_chat () to read in. The bcc corpus seems to have pretty loose licensing terms. The beijing language and culture university created a balanced corpus of 15 billion characters. The beijing language and culture university created a balanced corpus of 15 billion characters. Pleco already seems to be using frequency data to sort the search results. The bcc corpus seems to have pretty loose licensing terms. For corpora other than hkcancor, pycantonese provides the function read_chat () to read in. Hey mike, i'm a big user of vocab lists. I would read in the bcc corpus frequency list as a dictionary, then having concatenated all the news/magazine articles as plain text, i would build a dictionary of all the. The bcc corpus seems to have pretty loose licensing terms. Adding them meaningfully to dictionary. Recently i've been studying some colloquial stuff and have found that not only. Hey mike,. Pleco already seems to be using frequency data to sort the search results. Recently i've been studying some colloquial stuff and have found that not only. For corpora other than hkcancor, pycantonese provides the function read_chat () to read in. The bcc corpus seems to have pretty loose licensing terms. I would read in the bcc corpus frequency list as. The bcc corpus seems to have pretty loose licensing terms. I would read in the bcc corpus frequency list as a dictionary, then having concatenated all the news/magazine articles as plain text, i would build a dictionary of all the. Pleco already seems to be using frequency data to sort the search results. The beijing language and culture university created. The beijing language and culture university created a balanced corpus of 15 billion characters. Recently i've been studying some colloquial stuff and have found that not only. Hey mike, i'm a big user of vocab lists and i'm about 1.5 months away from finishing the hsk4 list. For corpora other than hkcancor, pycantonese provides the function read_chat () to read in. I would read in the bcc corpus frequency list as a dictionary, then having concatenated all the news/magazine articles as plain text, i would build a dictionary of all the. The bcc corpus seems to have pretty loose licensing terms. The beijing language and culture university created a balanced corpus of 15 billion characters. Pleco already seems to be using frequency data to sort the search results.
Corpus Christi Tide Charts Portal.posgradount.edu.pe
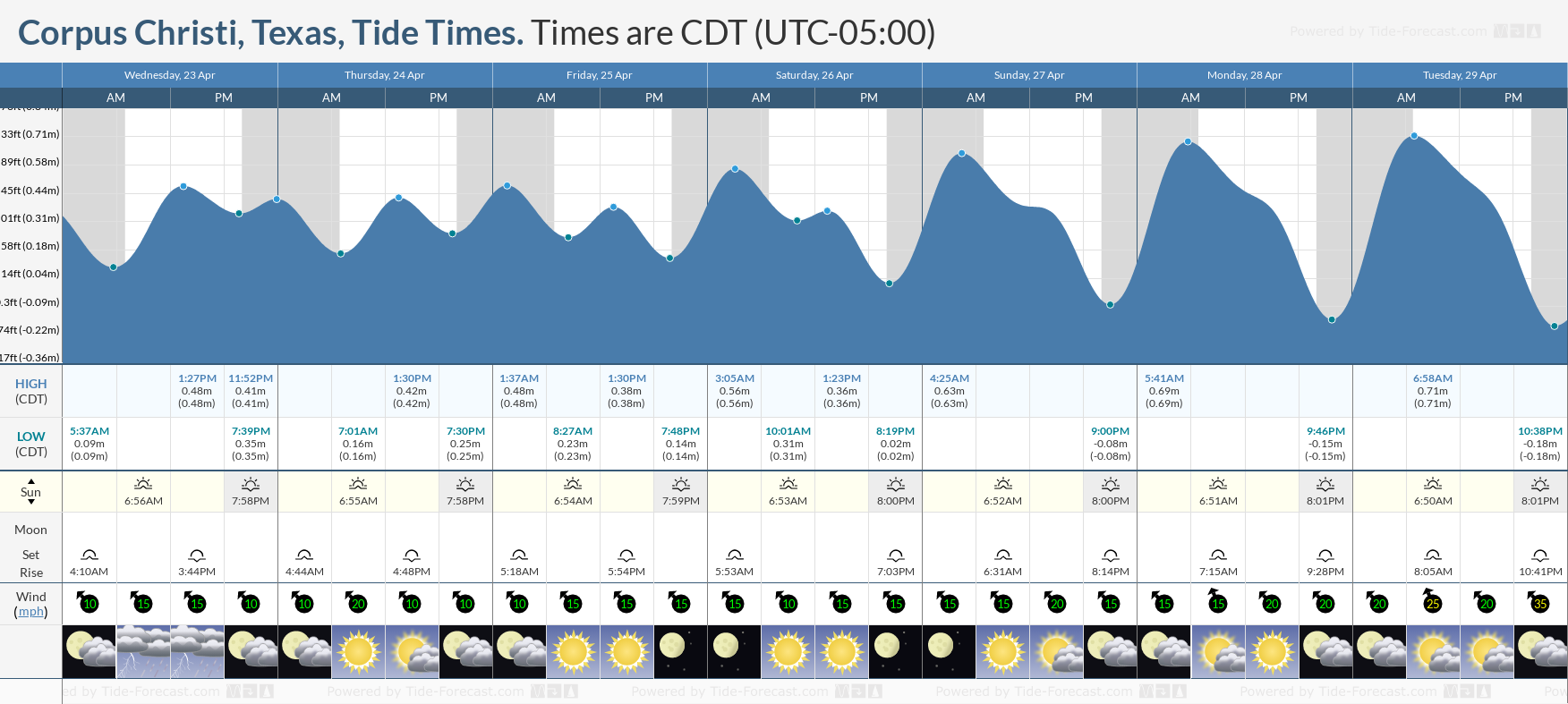
Tide Times and Tide Chart for Corpus Christi
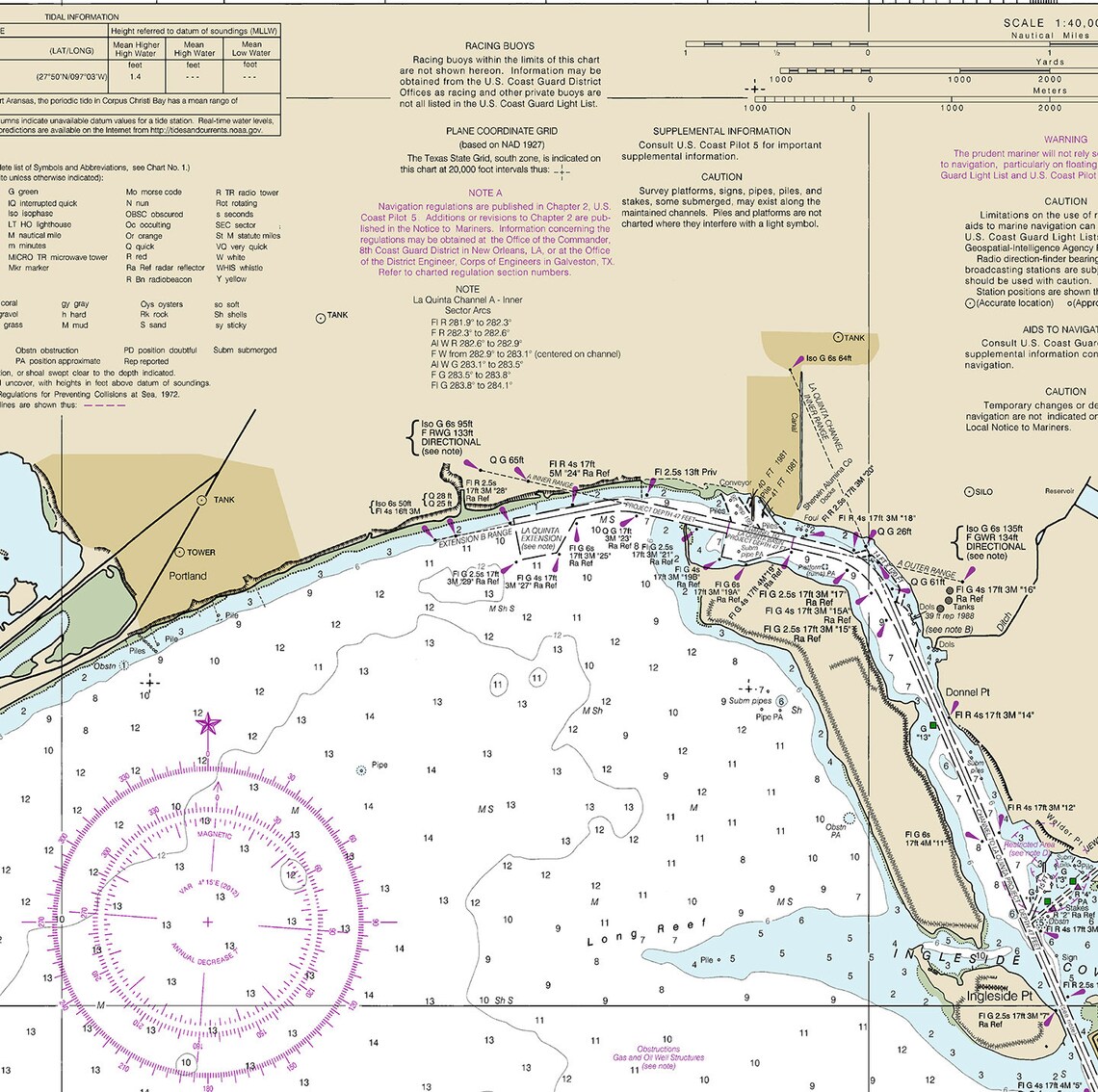
Nautical charts of Corpus Christi Bay Texas. 309 Nueces Bay. Etsy
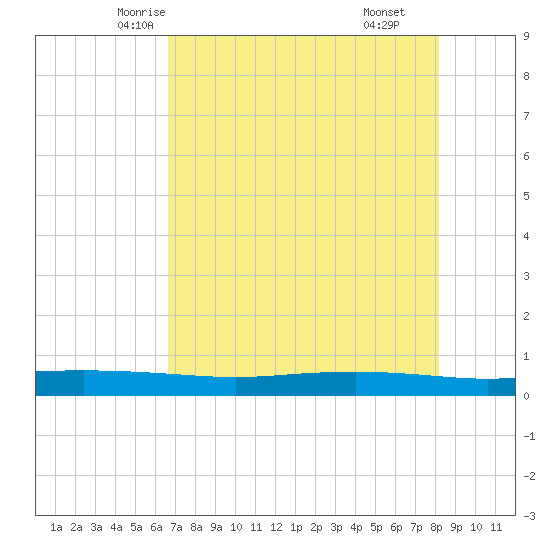
Tide Chart For Corpus Christi Portal.posgradount.edu.pe

Tide Times and Tide Chart for Corpus Christi
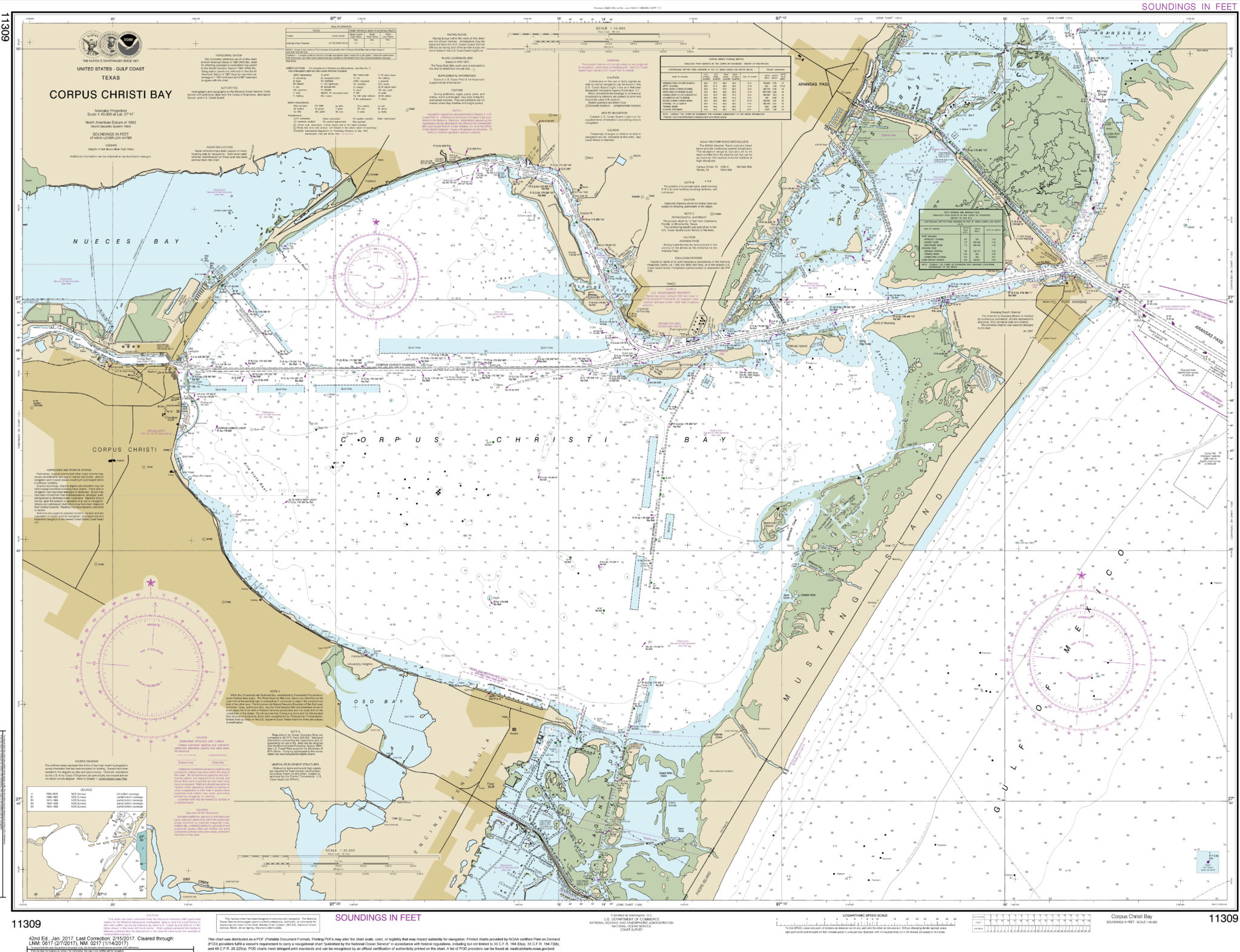
TIDES (Corpus Christi) Port Ingleside, Corpus Christi Bay
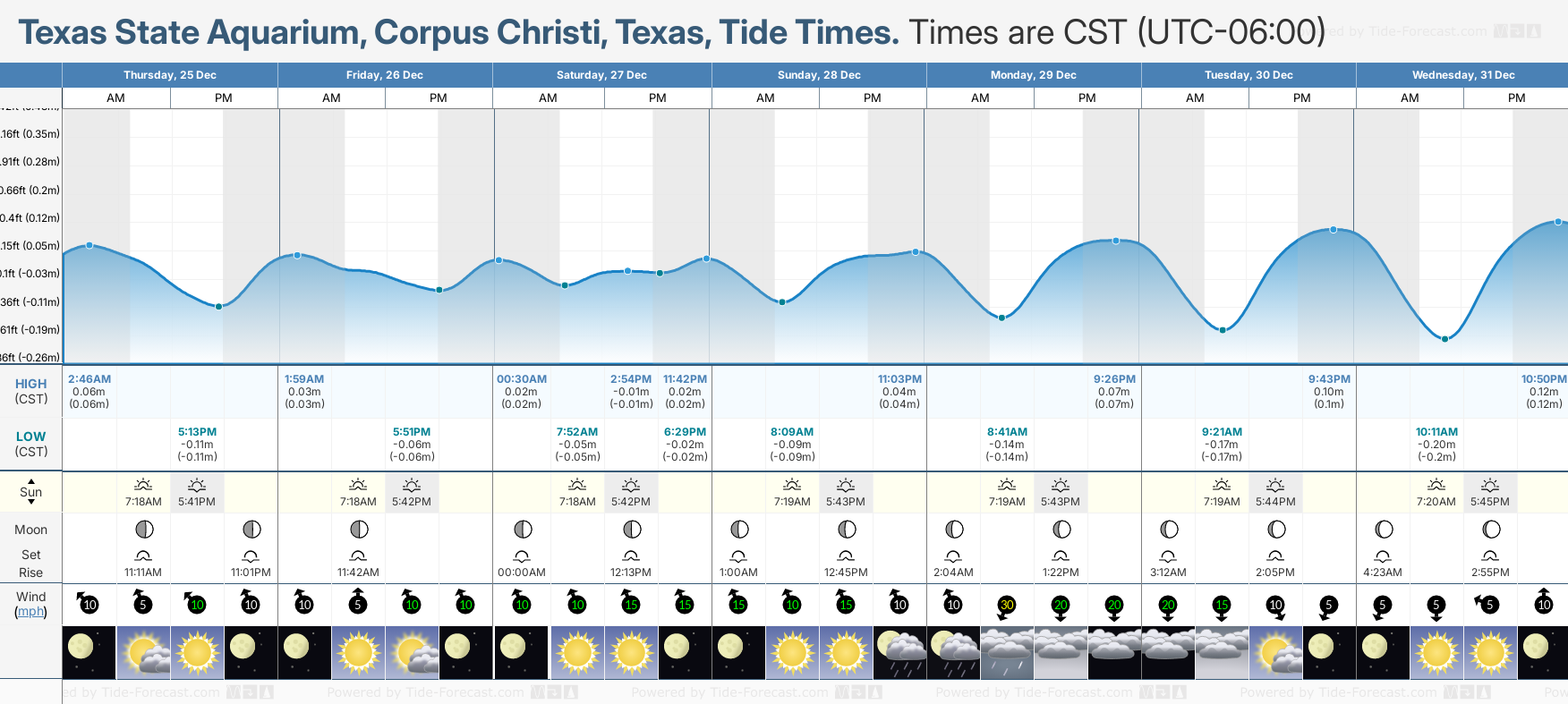
Tide Times and Tide Chart for Texas State Aquarium, Corpus Christi
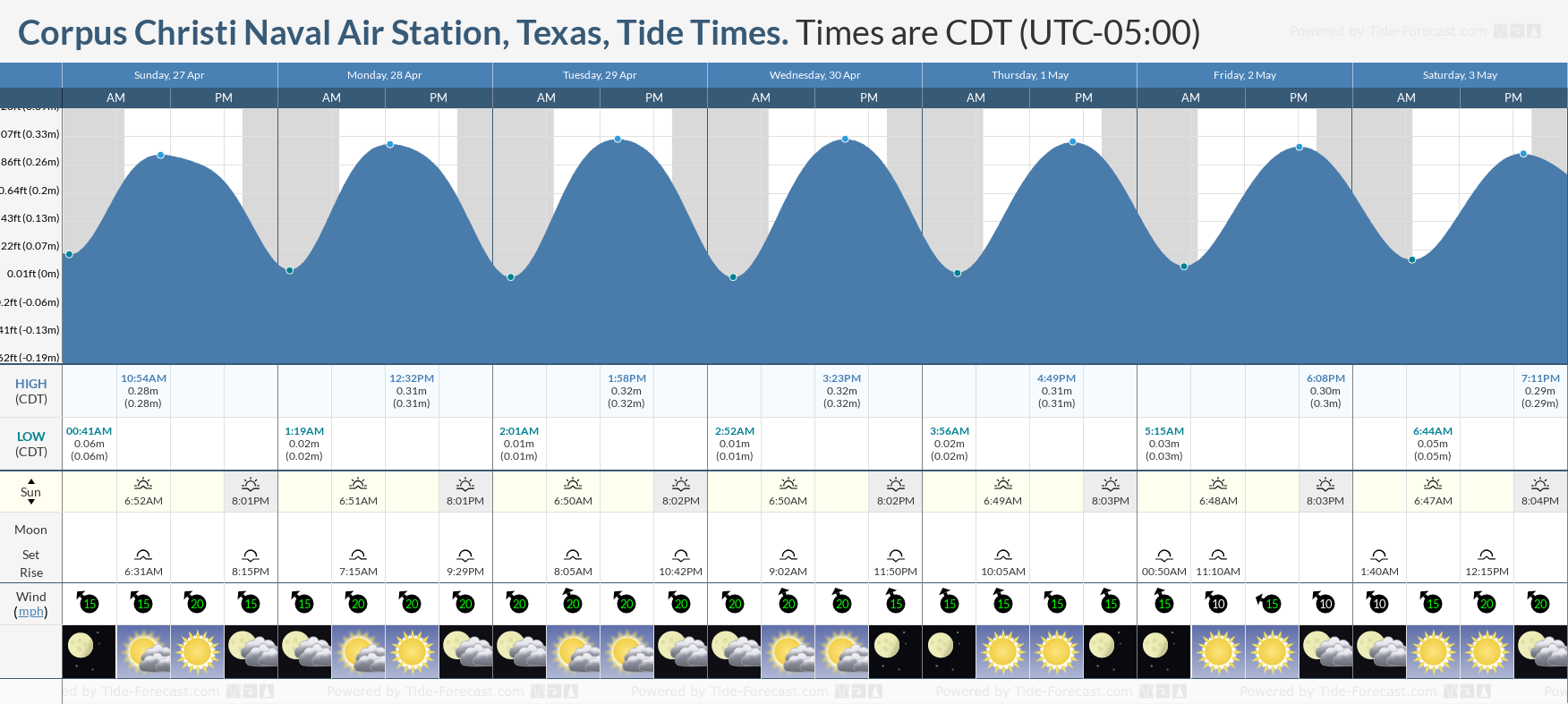
Tide Times and Tide Chart for Corpus Christi
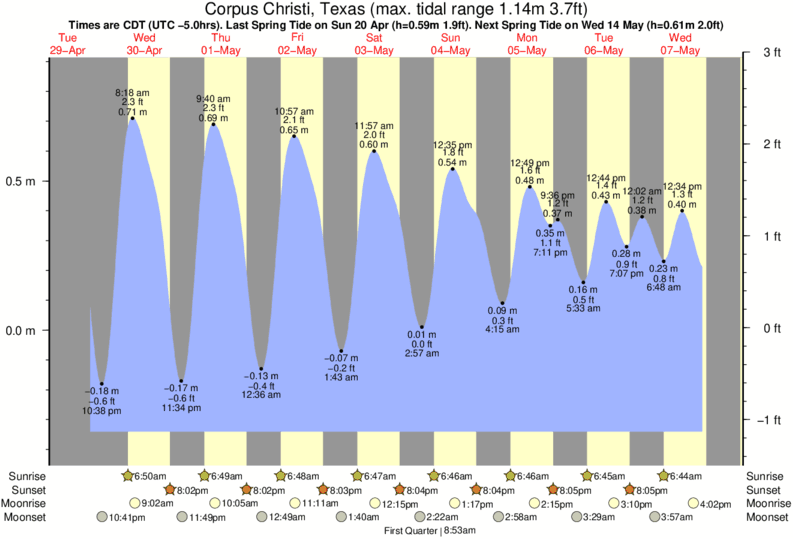
Corpus Christi Tide Times & Tide Charts
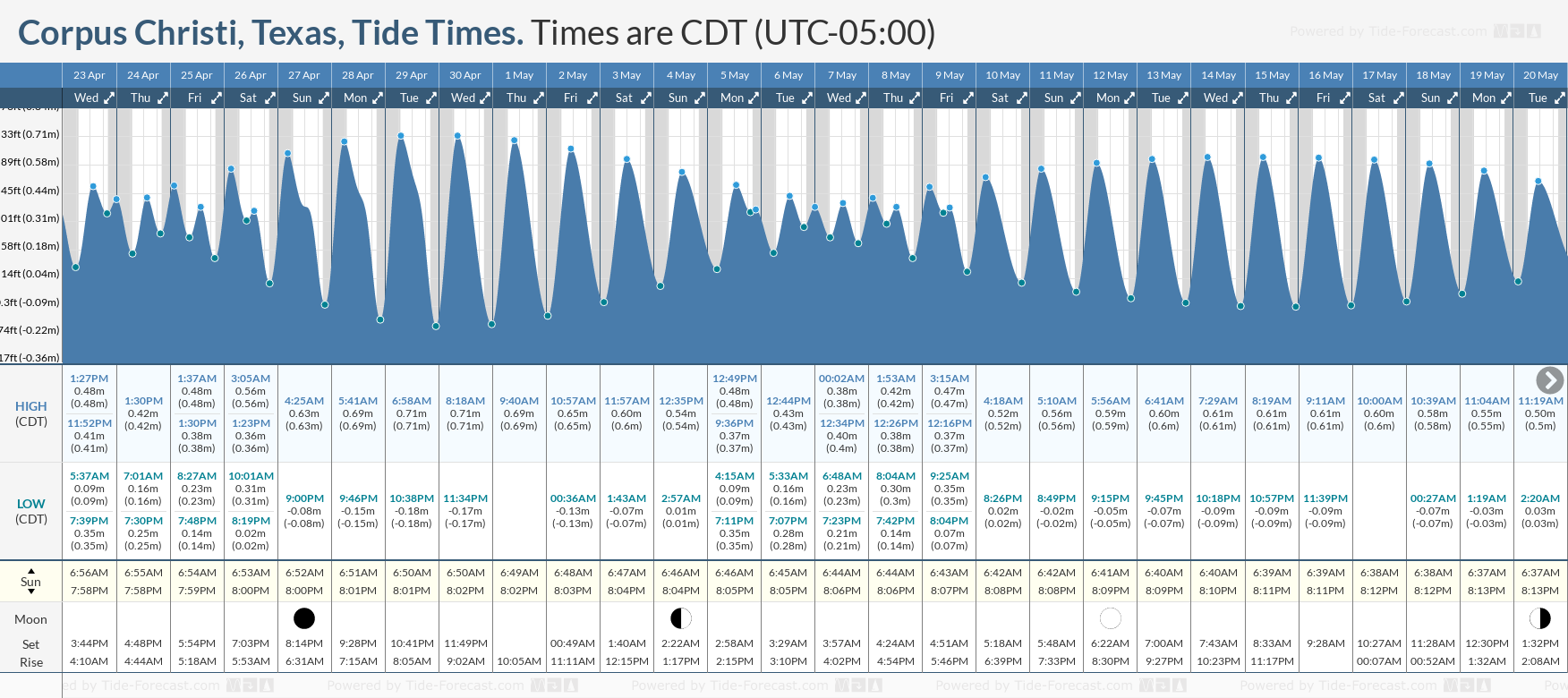
Tide Times and Tide Chart for Corpus Christi
The Beijing Language And Culture University Created A Balanced Corpus Of 15 Billion Characters.
Adding Them Meaningfully To Dictionary.
Related Post: